When humans look at a picture, they immediately notice important details such as edges, shapes, colours, and patterns. These details are then combined by the brain into a complete understanding of what the picture represents. For a computer, however, an image is nothing more than a large collection of numbers representing pixel values. Teaching a machine to recognise objects in an image requires a method that can handle large amounts of data while also preserving the relationships between pixels. This challenge gave rise to a special type of neural network known as the Convolution Neural Network.
Unlike ordinary networks that struggle with the size and complexity of image data, Convolution Neural Networks are designed to work in a way that is closer to how humans perceive visual information. They focus on smaller parts of an image first, detect useful features, and then combine those features to form a complete picture. This design has made Convolution Neural Networks the foundation of modern computer vision systems used in face recognition, medical imaging, self-driving cars, and many other fields.
Did You Know?
| Large CNNs can have millions of trainable parameters, which makes them very powerful but also computationally heavy. |
Why Do Regular Networks Struggle with Images?
A simple black-and-white image with a size of one hundred by one hundred pixels already contains ten thousand values. A coloured image, which includes three channels for red, green, and blue, contains thirty thousand values.
If we try to feed these values directly into a traditional neural network, two major problems occur:
- Too many inputs – The network becomes unnecessarily large, making the training process slow and inefficient.
- Loss of structure – The network cannot easily understand the spatial arrangement of pixels, such as the fact that eyes are positioned next to each other on a face or that wheels belong at the bottom of a car.
Convolution Neural Networks overcome both of these problems by processing the image in smaller sections while maintaining the relationships between nearby pixels.
How Convolution Neural Networks Look at Pictures
A Convolution Neural Network looks at the image as a grid of pixels, just like how the image actually appears. It examines small regions of this grid step by step, making it easier to detect important features. Instead of looking at all pixels at once, CNNs scan small parts of an image at a time, much like how humans focus on details before understanding the whole picture.
Think about how you look at a face: first you notice the eyes, then the nose, then the mouth, and finally your brain combines these parts into the overall image of a person. CNNs work in a very similar way.

Kernels (Filters)
The main tool used by Convolution Neural Networks is a filter, also called a kernel. A filter is a small grid, such as three by three, that slides across the image. At each step, it multiplies pixel values in that region and produces a new set of values that highlight specific patterns.
- Some filters detect edges in an image.
- Others detect textures or colour contrasts.
- Deeper layers of filters can identify complex shapes such as circles, wheels, or even faces.
This sliding process is called a convolution operation, which is where the network gets its name.
Step-by-step process:
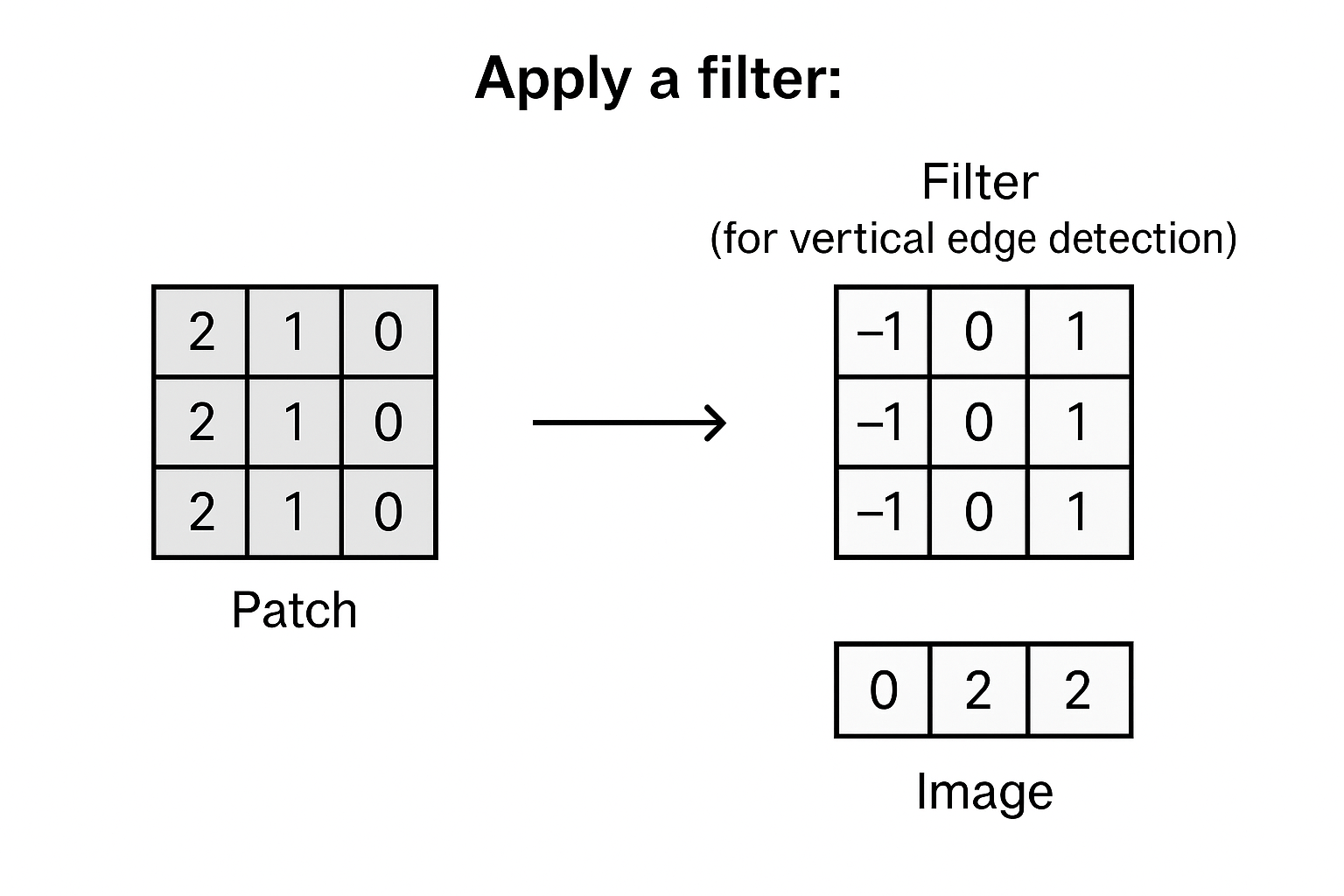
- Focus on small parts: The network does not try to understand the entire image at once. Instead, it looks at small patches, such as three by three or five by five sections of pixels. Example: A 5×5 part of an image
[12 14 11 9 10]
[13 15 14 8 11]
[ 9 12 16 10 13]
[10 11 15 13 14]
[ 8 9 12 11 12]
- Apply a filter: A filter (also called a kernel) is placed on this patch. Suppose the filter is designed to detect vertical edges. The filter slides over the patch, multiplies the numbers, and highlights areas where vertical lines are present. Example: Filter (for vertical edge detection)
[-1 0 1]
[-1 0 1]
[-1 0 1]
- Build features: As this filter moves across the image, the network creates a new map that shows where vertical edges exist. Another filter may do the same for horizontal edges, and yet another for curves or textures.
- Combine patterns: Once many filters have done their job, the network knows not only where the edges are, but also how they connect to form shapes such as a nose, a wheel, or a letter. These smaller details are combined layer by layer until the network understands the full object.
Pooling: Making Things Simpler
Once filters have extracted features, CNNs use another clever trick called pooling. Pooling reduces the size of the image while keeping important information intact.
The most common is max pooling, which takes the largest value from a region. For example, if you have a 4×4 block of numbers and apply 2×2 max pooling, each 2×2 region is replaced by its highest number, shrinking the block into 2×2 while keeping the strongest features.

Importance of pooling
- It reduces the number of calculations.
- It makes the network more robust to slight changes in the image (like a face being tilted).

For example, when a social media platform suggests tagging a friend in a photo, a Convolution Neural Network has analysed the features of the face and compared them to its stored knowledge.
Convolution Neural Networks represent a major breakthrough in teaching computers how to process visual information. By using filters to focus on small regions of an image and pooling to simplify the data, they are able to identify everything from simple edges to complex objects.
The ability of Convolution Neural Networks to detect meaningful features automatically has made them a cornerstone of deep learning, powering systems that are becoming part of everyday life, from unlocking phones with your face to assisting doctors in diagnosing disease.