Artificial Intelligence has traditionally worked with one kind of data at a time. It may be in the form of text, images, or sound. For example, earlier chatbots could only read and write text, while image recognition systems could only identify objects in photos. But in the real world, humans process information through many senses at once. We see, hear, read, and interpret everything together to understand our surroundings. This is where Multimodal AI comes in.
Multimodal AI aims to bring that same capability to machines. It allows AI systems to process and connect different types of information such as text, images, video, and audio to gain a more complete understanding of the world. This development has opened the door to new possibilities in technology, from AI models that describe images to those that can reason about a scene, answer questions, or even generate media.
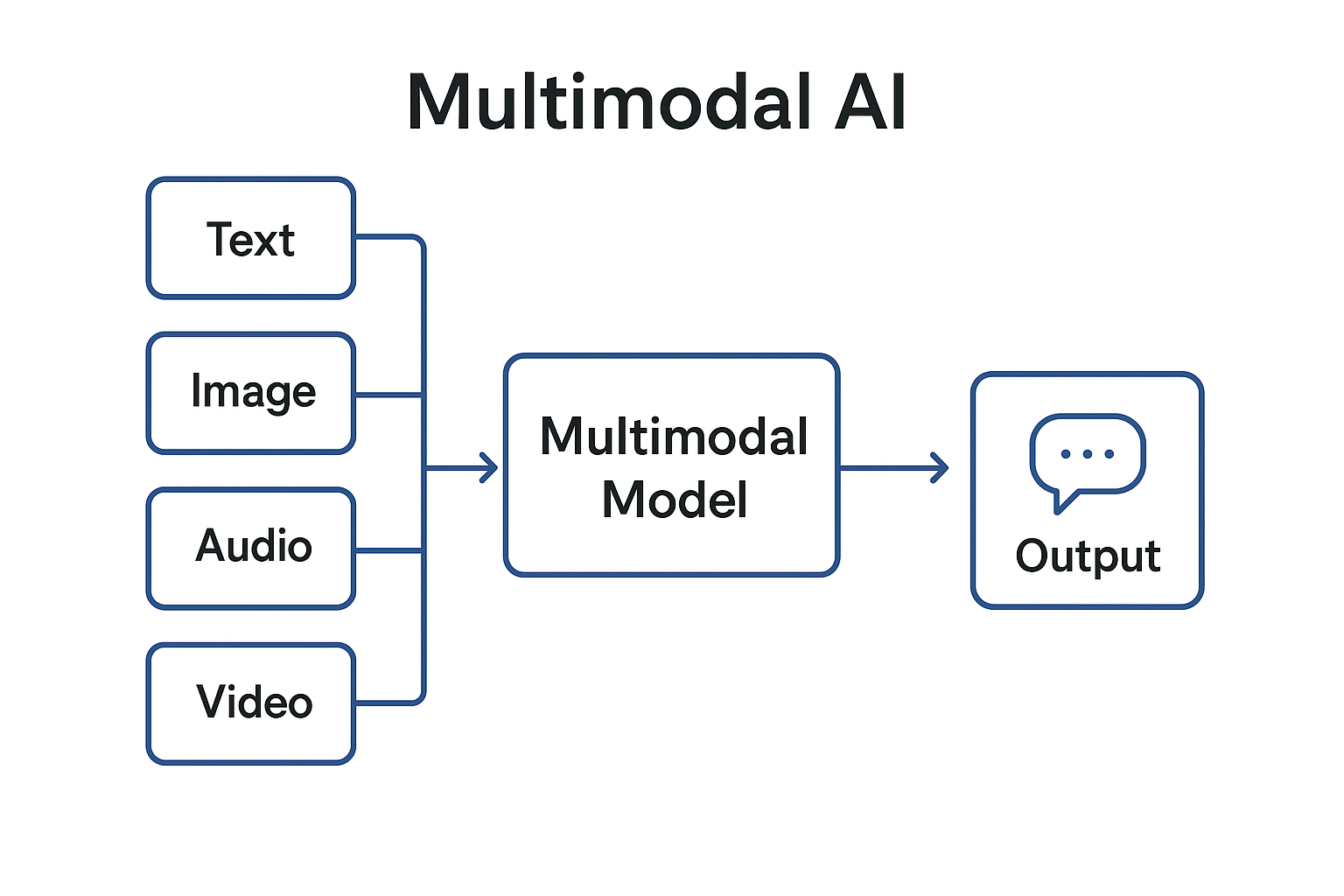
What is Multimodal AI?
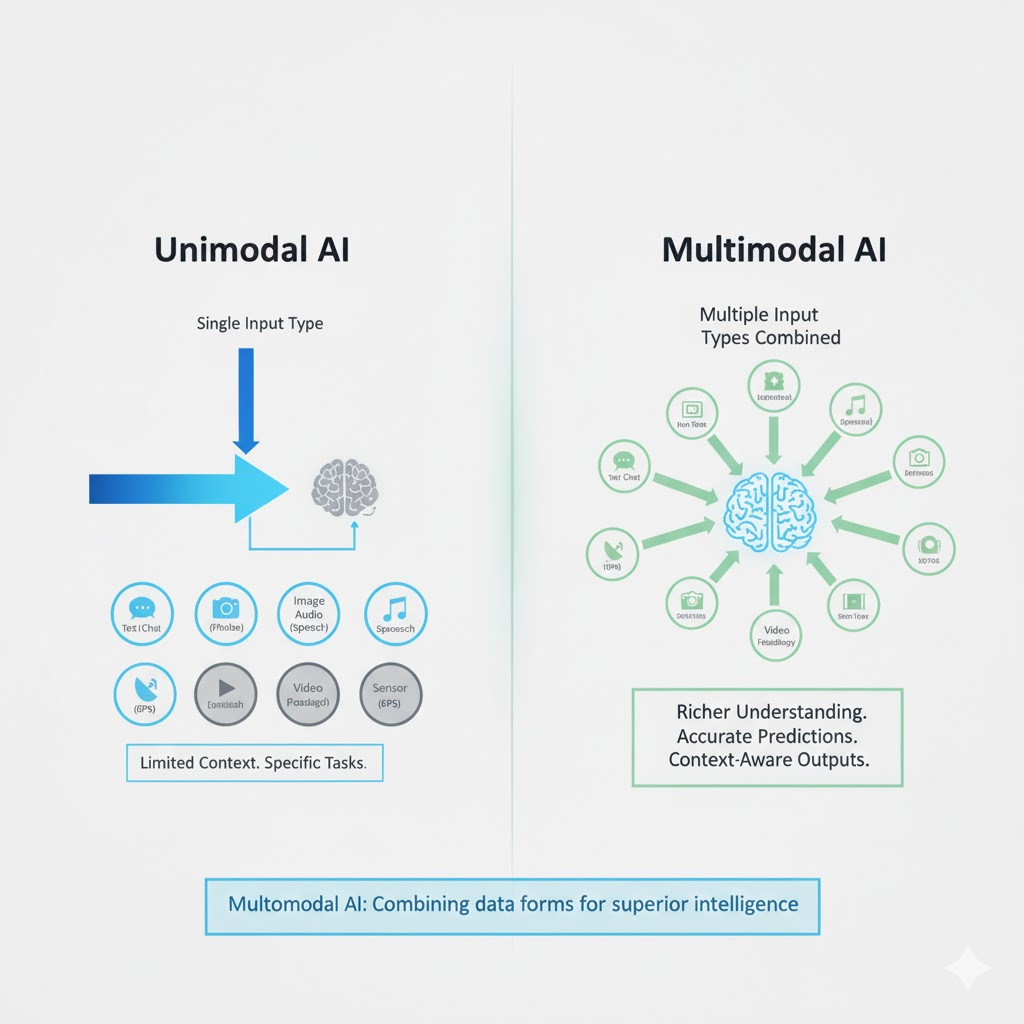
Multimodal AI refers to artificial intelligence systems that can handle more than one type of input or output. The word “modality” refers to a form of data: text, image, audio, video, or sensor readings. Traditional AI was “unimodal,” meaning it only worked with one type. Multimodal AI, on the other hand, combines these inputs to make more accurate and context-aware predictions or outputs.
For example:
- You can upload a photo of a menu in another language, and an AI system can read the text from the image and translate it instantly.
- A doctor can show a medical image to an AI model that also reads patient history notes to provide a better diagnosis.
- In self-driving cars, multimodal AI integrates visual data from cameras, radar signals, and text-based map instructions to make driving decisions.
These examples show how merging different kinds of data can make AI far more capable than before.
How Multimodal AI Works
Multimodal systems combine different types of inputs in a process often described as data fusion. Each data type is processed separately first, and then the information is merged into a shared space that the AI can understand.
- Data Encoding: Each type of data such as text, images, or sound is first converted into numerical form using encoders.
- Feature Extraction: The AI learns to detect useful features from each modality. For instance, in an image, it may recognize shapes, colors, and objects; in text, it identifies meanings and relationships between words.
- Fusion and Alignment: The extracted features are combined so that related data can be compared or understood together.
- Reasoning and Output: The model uses this joint understanding to answer questions, generate captions, summarize scenes, or produce new content.
For example, OpenAI’s CLIP model (Contrastive Language-Image Pretraining) learns to connect images with their captions. It can recognize that the image of “a red apple on a table” corresponds to that phrase. Similarly, GPT-4V (Vision) can look at an uploaded image, read the text in it, describe what’s happening, and even explain diagrams or charts. Google’s Gemini 1.5 can process large amounts of text, video, and audio together.For example, analyzing an hour-long lecture video and summarizing its key points.
Real-World Applications of Multimodal AI
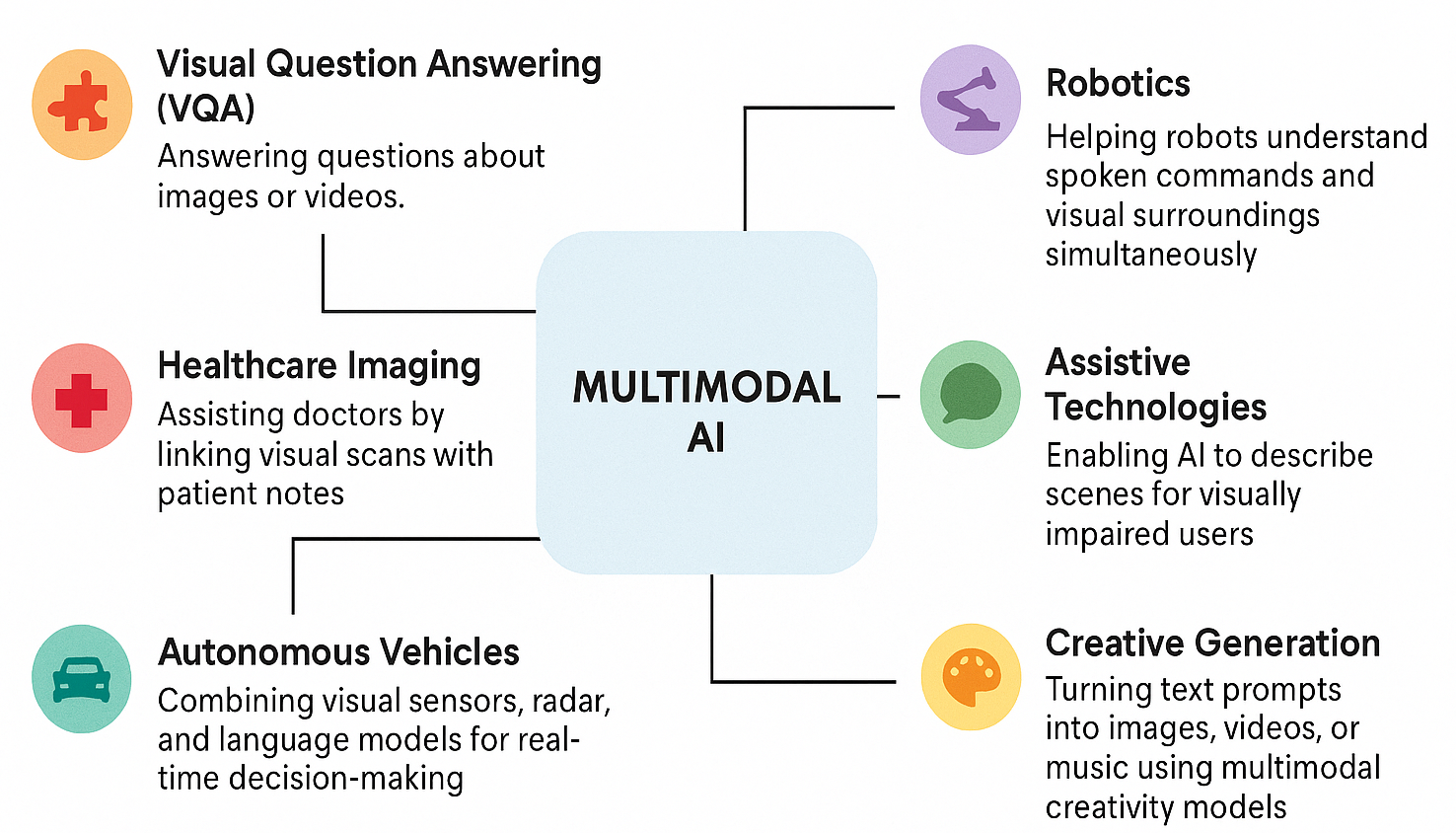
- Image Understanding with Text: AI can now read and understand images that contain text, such as scanned documents, street signs, or product labels. This is useful in translation apps like Google Lens, which can translate text seen through a phone camera in real time.
- Healthcare: Systems combine medical images like X-rays or MRIs with patient data and doctor’s notes to improve diagnosis accuracy. Models like PathAI and DeepMind’s MedPaLM are examples of such applications.
- Education: Multimodal learning tools can analyze videos, generate summaries, or answer questions about visual material, helping students learn from multimedia sources.
- Robotics and Automation: Robots that can see and hear, which have the ability to interpret both visual cues and voice commands are being developed for industrial use and home assistance.
- Accessibility: Multimodal AI supports people with disabilities. For instance, Microsoft’s Seeing AI app can describe a scene, read printed text aloud, and even recognize emotions in faces.
- Autonomous Vehicles: Self-driving systems combine cameras, radar, and GPS data to interpret their surroundings and make driving decisions.
These examples show how integrating multiple modes of information enables a more complete and intelligent system.

Benefits and Significance
The main advantage of multimodal AI is that it gives machines a more human-like way of understanding. Humans rarely rely on one sense, we combine what we see, hear, and read to make sense of things. Multimodal AI follows the same idea.
Some major benefits include:
- Contextual Understanding: The system can use one type of input to verify or complement another, improving accuracy.
- Human-Like Interaction: It allows for more natural communication between humans and machines, for example, by allowing users to talk to an AI assistant while showing it an image.
- Improved Accessibility: People who cannot see or hear can use multimodal AI tools that translate between visual and audio forms.
- Versatility: A single model can perform many different tasks rather than being limited to one.
Challenges and Limitations
Despite major progress, multimodal AI is still far from perfect. Integrating different data types is difficult because each one has unique structures and complexities.
Some of the main challenges include:
- Data Alignment Issues: Matching different modalities, like linking words in a sentence to parts of an image is not always accurate.
- Incomplete Understanding: Even advanced models sometimes misinterpret visual context or fail to detect humor, irony, or subtle cues in text.
- High Computational Cost: Training multimodal systems requires massive amounts of data and computing power.
- Bias and Fairness: If the datasets contain biased or unbalanced examples, the AI may reflect those biases in its predictions.
- Accuracy with Text in Images: Although AI can now read text from images (like signboards or handwritten notes), the results are not always consistent. Fine handwriting, low-quality images, or complex layouts can still cause errors.
- Limited Real-World Adaptation: While lab models perform well on benchmarks, they can struggle with the unpredictability of real-world data.
So, even though multimodal AI has made great progress, it’s still developing. It hasn’t reached the level of human perception and continues to face limitations in accuracy and understanding.
Did you Know?
Multimodal AI is also being explored in India for education and healthcare through research by IITs and AI labs focusing on regional language and visual learning tools.
Ethical and Societal Implications
Multimodal AI also raises new ethical and social questions. Because it deals with personal data like images, voices, and videos, privacy becomes a serious concern. There is also the growing problem of deepfakes and synthetic media, where AI-generated content can be mistaken for real evidence.
Transparency and accountability are equally important. If a multimodal model misinterprets an image or gives an incorrect response, it can be difficult to explain why. Researchers and policymakers are now focusing on responsible AI practices ensuring that these technologies are safe, fair, and explainable.
Multimodal AI represents a significant leap toward more intelligent and perceptive machines. By combining different types of information like text, images, sound, and video, these systems are starting to understand the world in a more human-like way.
However, it’s important to remember that this technology is still in progress. While modern systems can analyze pictures, read text within them, and even reason about what they see, they are not flawless. The journey toward truly multimodal intelligence will require better data, stronger ethical frameworks, and more efficient computing systems.
The progress so far, though, shows that AI is no longer limited to one sense. The next generation of intelligent systems will not only read or see, they will understand, connect, and perceive the world as we do.