Machine Learning is a popular domain of Artificial Intelligence. It allows computers to learn from data and improve their performance without being explicitly programmed. To achieve this, Machine Learning uses different methods of learning, popularly known as the types of Machine Learning. Among these, the two most widely used are Supervised Learning and Unsupervised Learning. Understanding the difference between these two types is essential for anyone starting in this field.
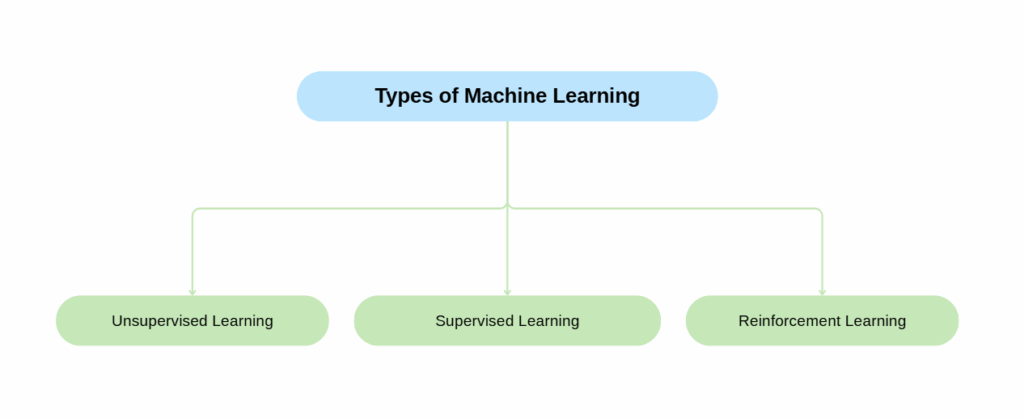
Types of Machine Learning
Machine Learning is divided into three categories broadly:
- Supervised Learning
- Unsupervised Learning
- Reinforcement Learning
In this article, we will focus on supervised vs unsupervised learning, explaining how each works, the algorithms behind them, and practical examples where they are applied in the real world.
What is Supervised Learning?
Supervised Learning refers to training a computer with the help of examples. The system is given input data along with the correct answers (labels). Over time, the computer learns the relationship between the two. Later, when new input arrives, the model can predict the correct label based on what it has already learned.
Imagine a voice recognition app on your phone. During training, the computer listens to audio clips of people saying numbers, and each clip is tagged with the correct digit (like “3” or “7”). Over time, the computer learns how different voices sound when saying the same number. Later, when you speak into the app, it can correctly identify the number you said, even if your voice is different from the training set.
Fun Fact!
| Voice assistants like Siri and Alexa learned to understand speech through supervised learning, trained on thousands of hours of labelled voice recordings. |
Another example is in medical diagnosis. If doctors provide a dataset of X-ray images marked as “healthy” or “diseased,” the computer will learn to identify which patterns are associated with illness. When a new X-ray is shown, the system can suggest whether it is normal or not.
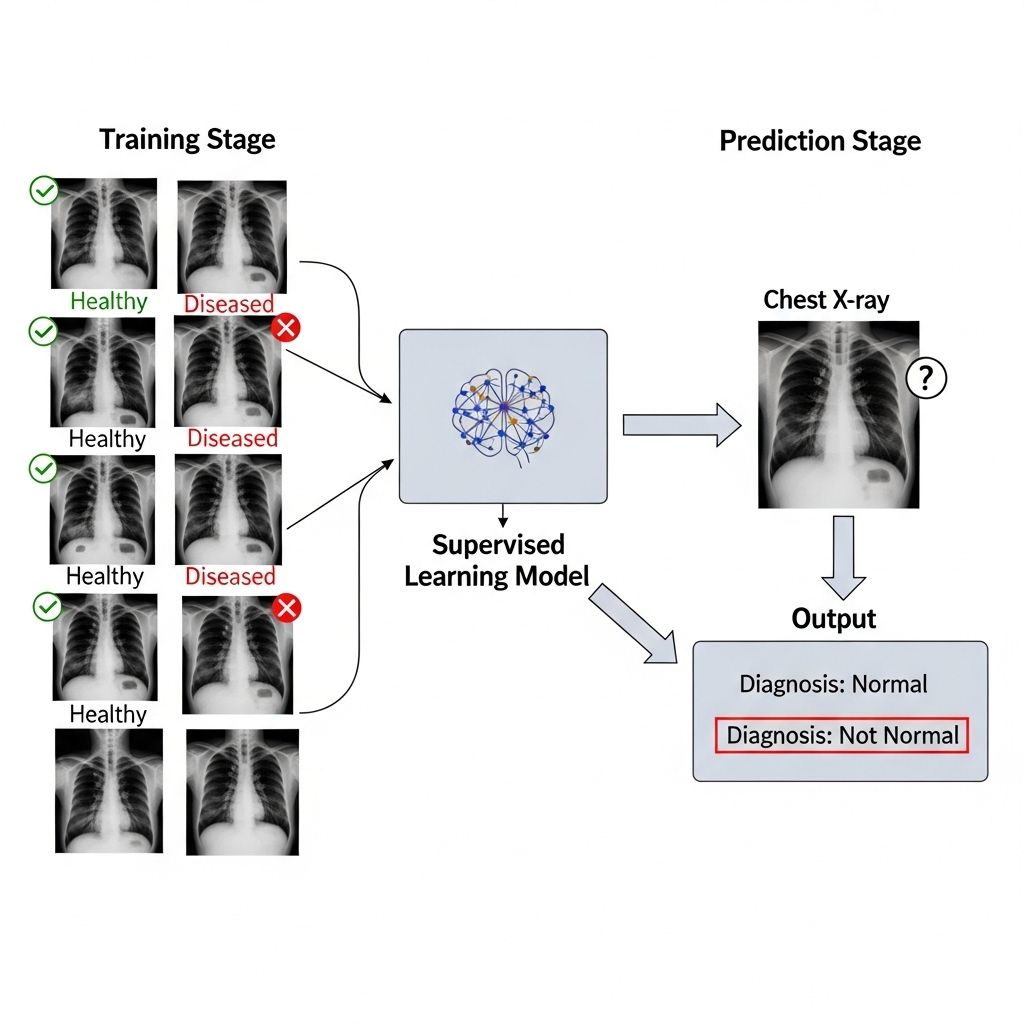
Algorithms in Supervised Learning
- Linear Regression: Linear Regression is used when we want to predict a number (a continuous value). It works by drawing the best possible straight line through a set of data points. Example: Suppose you want to predict the price of a house based on its size. If we plot the size of houses on one axis and their prices on the other, Linear Regression will find a line that best represents the relationship between size and price. Using this line, we can estimate the price of a new house if we know its size.
- Logistic Regression: Despite its name, Logistic Regression performs classification rather than predicting numbers. It helps answer questions with two outcomes, like yes/no, true/false, or safe/fraudulent. Example: A bank uses Logistic Regression to check if a loan applicant will repay or default. It takes inputs like income, age, and credit history, and outputs either “approved” or “rejected.”
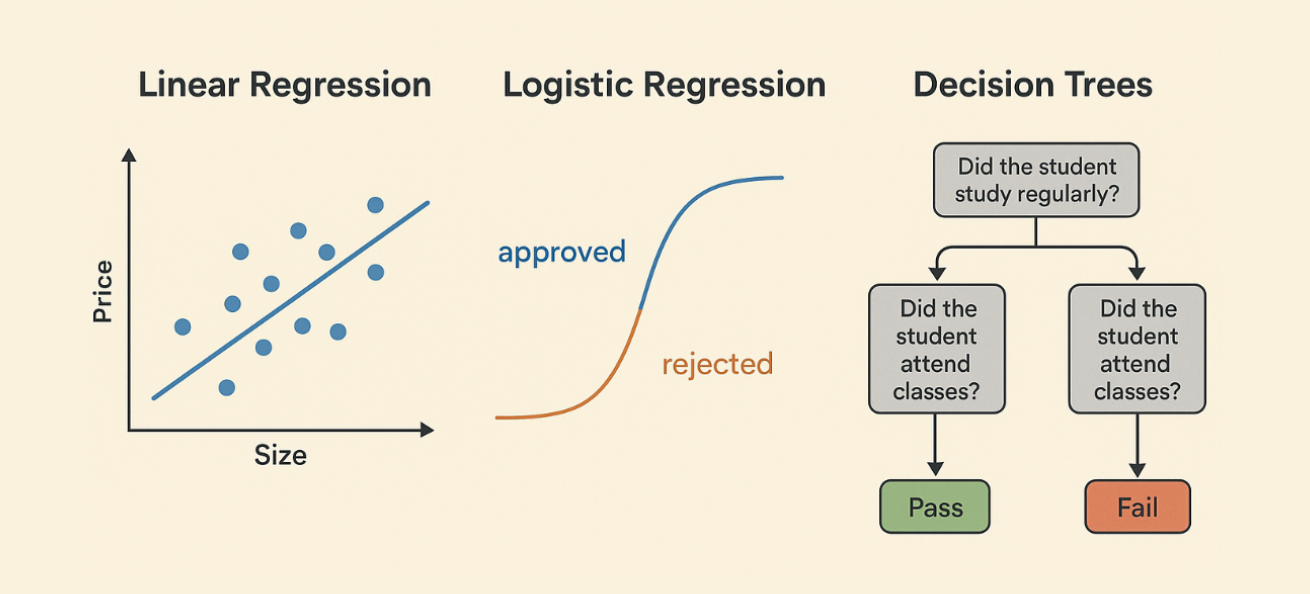
- Decision Trees: A Decision Tree works like a flowchart, splitting data into smaller groups at each question until it reaches a decision. Each branch shows a choice, and the end gives the result.
Example: In predicting whether a student will pass or fail, the tree might first ask: Did the student study regularly? If yes, move one way, if no, move another. The next question might be: Did the student attend classes? Step by step, the tree narrows down to a final prediction.
What is Unsupervised Learning?
Unsupervised Learning, unlike supervised learning, works without labelled data. The computer receives raw information without answers and finds patterns, similarities, or differences on its own.
Consider a music streaming service. You listen to various songs, but you never tell the system which ones belong to “pop,” “jazz,” or “classical.” Still, the computer can analyse the features of each song (tempo, instruments, rhythm) and group them into clusters. Later, it recommends playlists based on your listening patterns.
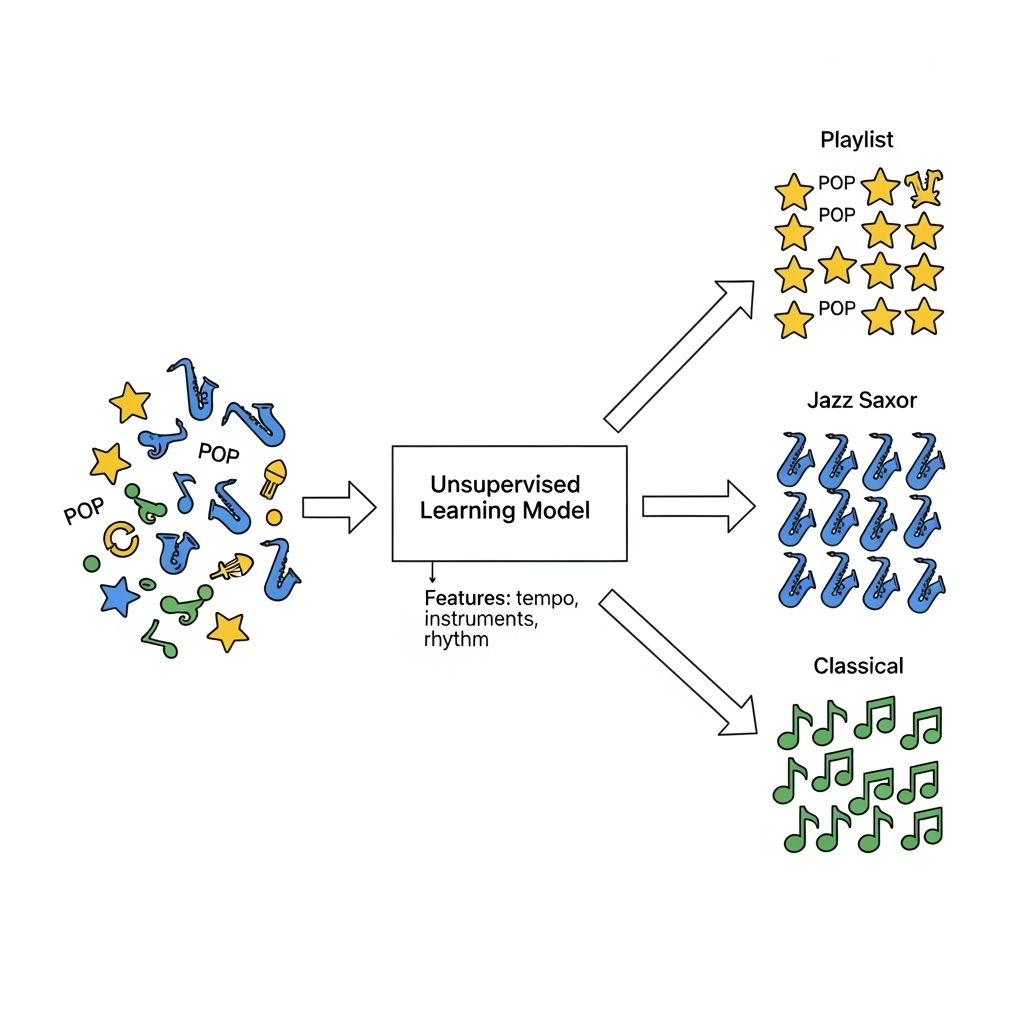
Another example is market research. Retailers can feed customer purchase records into an unsupervised learning system. The computer may find that one group of customers buys sports equipment and energy drinks together, while another group prefers gardening tools and seeds. Without anyone telling it what the groups are, the computer has discovered hidden patterns.
Algorithms in Unsupervised Learning
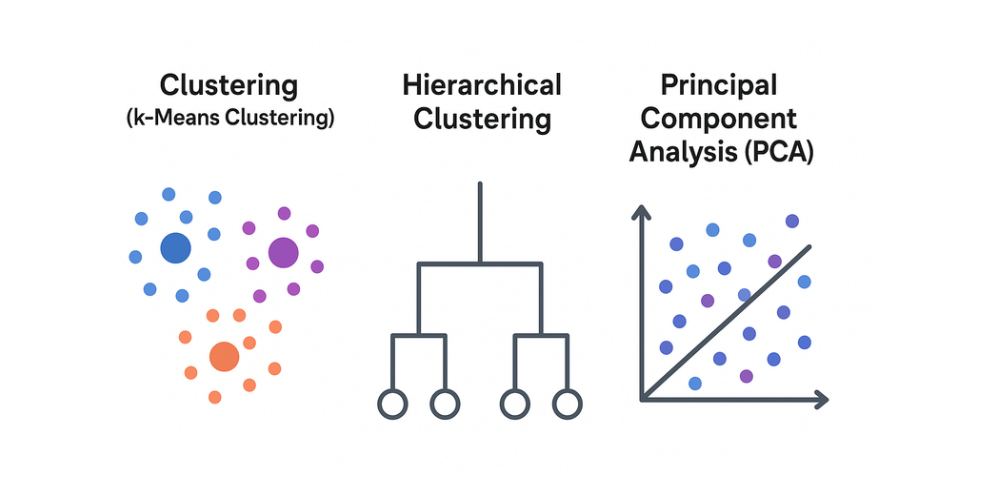
- Clustering (like k-Means Clustering): This algorithm divides data into a fixed number of groups (clusters). You tell it how many groups you want, and it tries to put similar data points together. Each group defines a “center,” and the algorithm assigns data points to the nearest center. Example: A shopping website can use k-Means to group customers. One cluster may be people who buy electronic gadgets, another may be those who buy clothes, and another for those who buy groceries.
- Hierarchical Clustering: Instead of deciding the number of groups in advance, this algorithm builds clusters step by step. It starts by treating each item as its own group, then combines the closest ones until larger groups form. The result looks like a tree of clusters. Example: In a library, organisers may first group books by author, then merge those groups into larger ones like “mystery novels” or “science fiction.”
Did You Know?
| Hierarchical clustering does not always require you to pre-set the number of groups. You can decide where to “cut” the tree (dendrogram) at any level, which means the same dataset can reveal different grouping patterns depending on how detailed you want the clusters to be. |
- Principal Component Analysis (PCA): The PCA algorithm handles datasets with too many features by reducing them to the most important ones that capture most of the information. PCA reduces the number of features by keeping only the most important ones that capture most of the information. This makes patterns easier to see without losing too much detail. Example: In analysing student performance, there might be dozens of test scores, attendance records, and activity data. PCA can reduce these to just a few important factors like “academic strength” and “class participation,” which still explain overall performance.
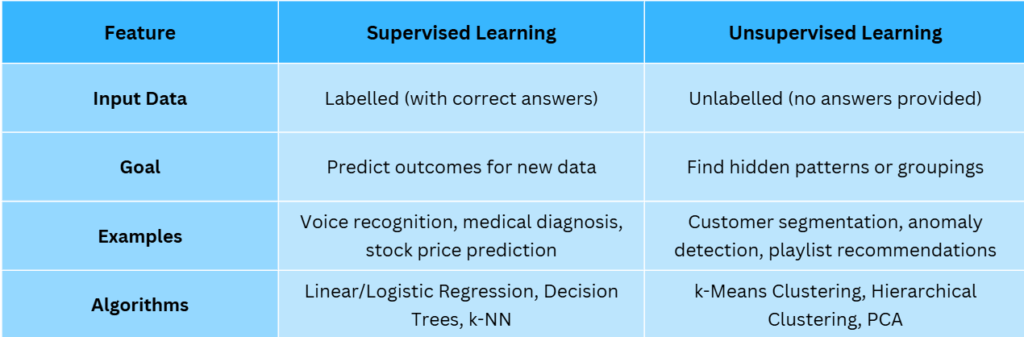
Supervised Learning and Unsupervised Learning are two key ways in which machines learn. Supervised Learning uses labelled data to make predictions, while Unsupervised Learning looks for hidden patterns in un-labelled data. Both play a major role in everyday applications, from medical tools to shopping recommendations.
Reinforcement Learning is another important approach, where machines learn by receiving rewards and making mistakes. In the next article, we will explore how Reinforcement Learning works and why it is becoming so important in fields like robotics and game-playing AI.